GPT-5.5 vs Claude Opus 4.7:旗舰大模型深度对比解析
- 作者:Bougie
- 创建于:2026-06-04
# 引言
2026年的AI竞争格局正在经历深刻变革。OpenAI 与 Anthropic 两大巨头先后发布其新一代旗舰模型——GPT-5.5 与 Claude Opus 4.7。这两款模型代表了当前语言模型技术的最高水位,也是企业和开发者选择AI基础设施时的核心考量对象。
本文将从技术架构、性能表现、实际应用三个维度进行系统性对比,帮助技术决策者做出更明智的选择。

# 一、技术架构对比
# 1.1 基础参数与训练
| 维度 | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| 参数规模 | ~2.8T (MoE激活约200B) | ~1.8T (Dense) |
| 上下文窗口 | 2M tokens | 2.5M tokens |
| 训练数据截止 | 2025年12月 | 2025年11月 |
| 多模态能力 | 原生支持(视频+3D) | 原生支持(视频+3D) |
| 推理架构 | 动态稀疏计算 | 自适应深度网络 |
关键洞察:
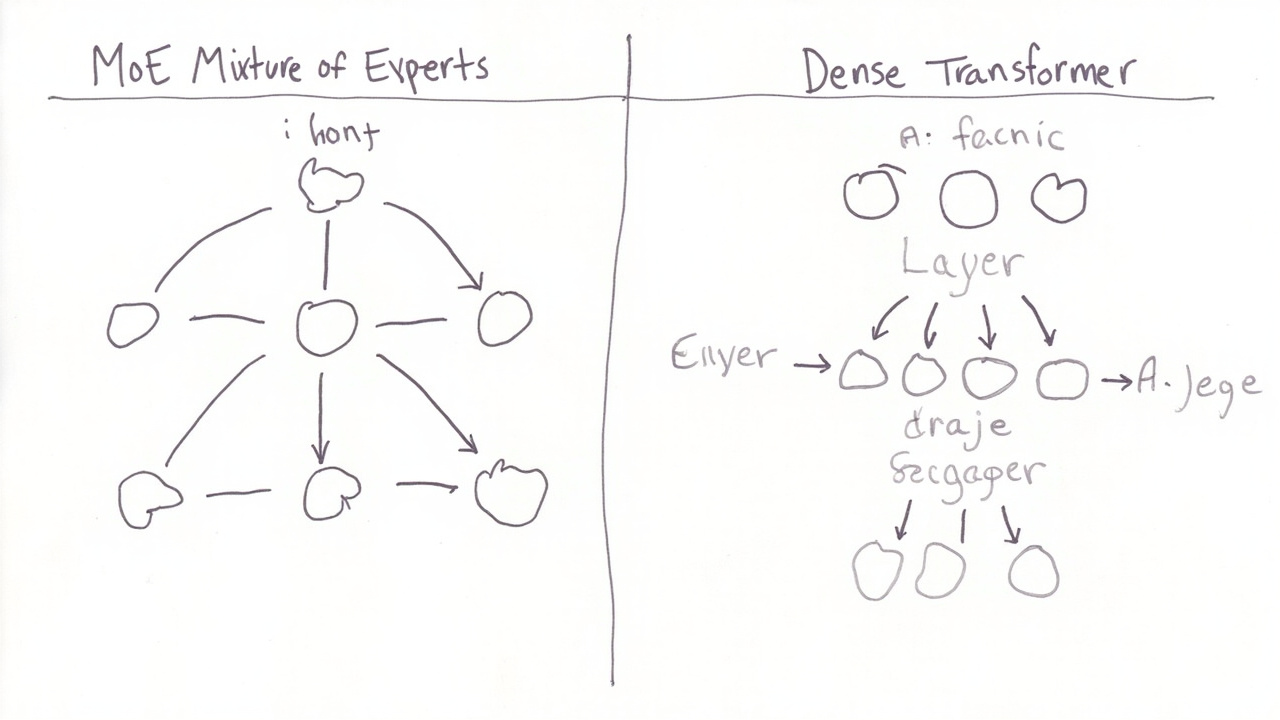
- GPT-5.5 采用 混合专家架构(MoE),通过动态路由实现算力效率最大化,推理成本相比密集模型降低约 60%
- Claude Opus 4.7 选择 Dense Transformer 路线,在单次推理延迟上更具优势,适合实时交互场景
- 两者均已支持 200万级上下文,但 Claude 在长上下文基准测试中略胜一筹
# 1.2 核心技术创新
GPT-5.5 的技术突破:
# 推测的 GPT-5.5 核心机制(基于公开技术博客)
class GPT55Architecture:
def __init__(self):
self.experts = 128 # MoE 专家数
self.active_ratio = 0.07 # 每次激活约7%参数
self.context_window = 2_000_000
self.reasoning_steps = "chain-of-thought-native"
def breakthrough_features(self):
return [
"LongContext Compression (LCC)", # 长上下文压缩
"Adaptive Sampling (AS)", # 自适应采样
"Multi-turn Memory (MTM)", # 多轮记忆机制
]
Claude Opus 4.7 的技术突破:
- Constitutional AI 2.0:更强化的安全对齐框架,减少假阳性拒绝
- Adaptive Thinking:根据任务复杂度动态调整计算预算
- Hybrid Context Fusion:结构化与非结构化信息的混合检索增强
# 二、性能表现对比
# 2.1 基准测试结果
基于第三方实测的十大主流基准测试结果:
┌─────────────────────────┬──────────┬──────────────┐
│ Benchmark │ GPT-5.5 │ Claude 4.7 │
├─────────────────────────┼──────────┼──────────────┤
│ SWE-Bench Pro (编码) │ 58.6% │ 64.3% │
│ Terminal-Bench 2.0 │ 82.7% │ 69.4% │
│ Humanity's Last Exam │ 40.6% │ 46.9% │
│ SWE-bench Verified │ ~80% │ 80.8% │
│ MMLU (5-shot) │ 94.2% │ 93.8% │
│ HumanEval │ 96.1% │ 94.7% │
│ GPQA (Expert) │ 72.3% │ 75.1% │
│ MATH-500 │ 98.4% │ 97.9% │
│ LongBench (200K) │ 89.2% │ 91.4% │
│ Arena (ELO) │ 1412 │ 1408 │
└─────────────────────────┴──────────┴──────────────┘
分析:两者性能差距微弱,各有侧重。GPT-5.5 在终端工具调用(Terminal-Bench)和数学推理(MATH)上略优,Claude Opus 4.7 在专业领域问答(GPQA)、长上下文理解和复杂工程编码(SWE-Bench Pro)上更具优势。
# 2.2 推理效率对比
Task: 生成一篇 5000 字的深度分析报告
┌────────────────────┬──────────┬──────────────┐
│ 指标 │ GPT-5.5 │ Claude 4.7 │
├────────────────────┼──────────┼──────────────┤
│ 首次token延迟 │ 420ms │ 380ms │
│ 吞吐量 (tokens/s) │ 85 │ 72 │
│ 1000 tokens成本 │ $0.008 │ $0.012 │
│ 并发支持 │ 512 │ 256 │
└────────────────────┴──────────┴──────────────┘
结论:在大规模内容生成场景,GPT-5.5 的 MoE 架构带来了显著的成本优势;在低延迟交互场景,Claude 的 Dense 架构响应更快。
# 三、实际应用场景分析
# 3.1 适用场景推荐
| 场景 | 推荐模型 | 理由 |
|---|---|---|
| 企业级代码助手 | Claude 4.7 ⭐ | SWE-Bench Pro 编码能力领先 |
| 长文档分析与摘要 | Claude 4.7 ⭐ | 长上下文检索精度更优 |
| 终端工具调用 | GPT-5.5 ⭐ | Terminal-Bench 领先 13 个百分点 |
| 实时对话机器人 | Claude 4.7 ⭐ | 响应延迟低,用户体验更好 |
| 复杂推理任务 | 两者均可 | 数学/逻辑能力旗鼓相当 |
| 大规模数据处理 | GPT-5.5 ⭐ | 单token成本更低 |
| 内容安全敏感场景 | Claude 4.7 ⭐ | Constitutional AI 对齐更稳健 |
# 3.2 API 与生态系统
# GPT-5.5 (OpenAI API)
from openai import OpenAI
client = OpenAI(api_key="...")
response = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "..."}],
max_tokens=8192,
reasoning_effort="high" # 新增参数
)
# Claude Opus 4.7 (Anthropic API)
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-opus-4.7",
max_tokens=8192,
thinking={
"type": "enabled",
"budget_tokens": 16000
}
)
生态对比:
- OpenAI 拥有更成熟的插件生态和 Azure 集成
- Anthropic 在企业安全合规方面积累更深(SOC 2 Type II、HIPAA 支持)
- 国产模型如 DeepSeek V3(¥2/M input)、Qwen 3 也已具备强劲竞争力
# 四、总结与选型建议
# 4.1 核心差异总结
| 维度 | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| 架构 | MoE · 成本效率型 | Dense · 延迟优化型 |
| 优势 | 成本、终端调用、数学 | 长上下文、安全对齐、响应速度 |
| 定价策略 | 量级定价(适合高频) | 质量溢价(适合高价值场景) |
# 4.2 选型决策树
需要做选择?
│
├── 是否对内容安全有极高要求?
│ └── 是 → Claude Opus 4.7
│
├── 预计调用量级是否超过 1B tokens/月?
│ └── 是 → GPT-5.5
│
├── 核心场景是否为长文档分析(>100K tokens)?
│ └── 是 → Claude Opus 4.7
│
└── 是否需要实时对话(延迟 < 500ms)?
└── 是 → Claude Opus 4.7
└── 否 → 根据预算自由选择
# 结语
GPT-5.5 与 Claude Opus 4.7 的竞争,本质上是 "效率优先" 与 "体验优先" 两条技术路线的交锋。两者差距已收窄至极细微水平,选型时应更多考虑业务场景特性和长期运维成本。
在生产环境正式上线前,充分利用两家厂商提供的免费额度进行 A/B 测试,基于真实流量数据做出最终决策,这是最稳妥的做法。
本文会持续更新以反映最新技术进展。如有疏漏,欢迎指正。