OpenClaw 启示录:开源 AI 助理的爆发
- 作者:Bougie
- 创建于:2026-06-11
- 更新于:2026-06-11

凌晨两点,我的老友张给我发来一条消息:"你知道吗,我的电脑现在比我老婆还了解我的文件结构。"
这听起来像是一个程序员深夜的胡言乱语,但老张是认真的。上个月,他把 OpenClaw 部署在自己的 Mac Mini 上,给它开放了文件系统的只读权限。然后——他让 AI 自己分析了十年积累的代码仓库、文档和笔记。
"我从来没想过我的『代码规范.md』文件会和 2019 年的某个 API 设计文档产生关联,"老张说,"但它找到了,还自动帮我生成了项目知识图谱。"
这听起来像是科幻小说,但 OpenClaw 正在让这一切变得稀松平常。
# 当 AI 开始「动手做事」
在开始深入技术细节之前,我想先聊聊是什么让 OpenClaw 如此特别。
我们用过太多"只会说话"的 AI 助手了——它们能写诗、能分析数据、能在聊天框里给你一堆建议,但当你真的想让它们帮你创建一个文件、运行一条命令、或者自动化某个日常流程时,它们就哑火了。
OpenClaw 不一样。它是那种能动手做事的 AI。
上周我用它做了一件小事:我对它说,"帮我清理一下 Downloads 文件夹,把超过三个月的安装包移到归档目录,然后统计一下各类文件的占用空间。"
三秒钟后,它不仅完成了操作,还给我返回了一份清晰的报告:
- 移除了 23 个过期安装包,释放 4.7GB
- 归档了 8 个可能需要保留的旧版本软件
- 当前文件分布:视频 12.3GB、文档 2.1GB、压缩包 1.2GB
这不是什么复杂的任务,但关键是——它真的做了,而不是给我一堆文字建议。
这听起来理所当然,但当你真正用上这种"能动手"的 AI 之后,你会发现传统 AI 助手的局限性是多么令人沮丧。
# OpenClaw 是什么?
让我们来正式认识一下 OpenClaw。
OpenClaw 是一个开源的本地优先 AI 助理框架,由 Peter Steinberger 创立,采用 MIT 协议开源。
Peter Steinberger 是一位值得关注的开发者。在此之前,他在 iOS 开发和跨平台框架领域深耕多年,以对用户体验的极致追求著称。OpenClaw 延续了他一贯的产品理念——让技术服务于人,而不是让人服务于技术。
MIT 协议的选择意味深长。在 AI 助手这个赛道上,大多数产品都是闭源的——无论是 Microsoft Copilot、Apple Intelligence 还是各种商业化 AI 助理,用户都无法深入了解它们的运作机制,更无法根据自己的需求进行定制。OpenClaw 的 MIT 协议让这一切变得不同:你可以自由使用、修改、分发,甚至基于它构建商业产品。
这在当前的 AI 生态中,是一股难得的清流。
# 爆发背后的数据
如果说功能特性是 OpenClaw 的"内力",那么数据增长就是它"外功"的体现。
在 GitHub 上,OpenClaw 的星标数量在短短四个月内从 9,000 飙升至 188,000。这个数字意味着什么?
让我们做一个横向对比。在开源世界的历史上,星标增长如此之快的项目屈指可数。Linux 内核用了二十多年才积累起庞大的星标基数,而 React——这个改变了前端开发范式的框架——在早期也没有这种增长速度。
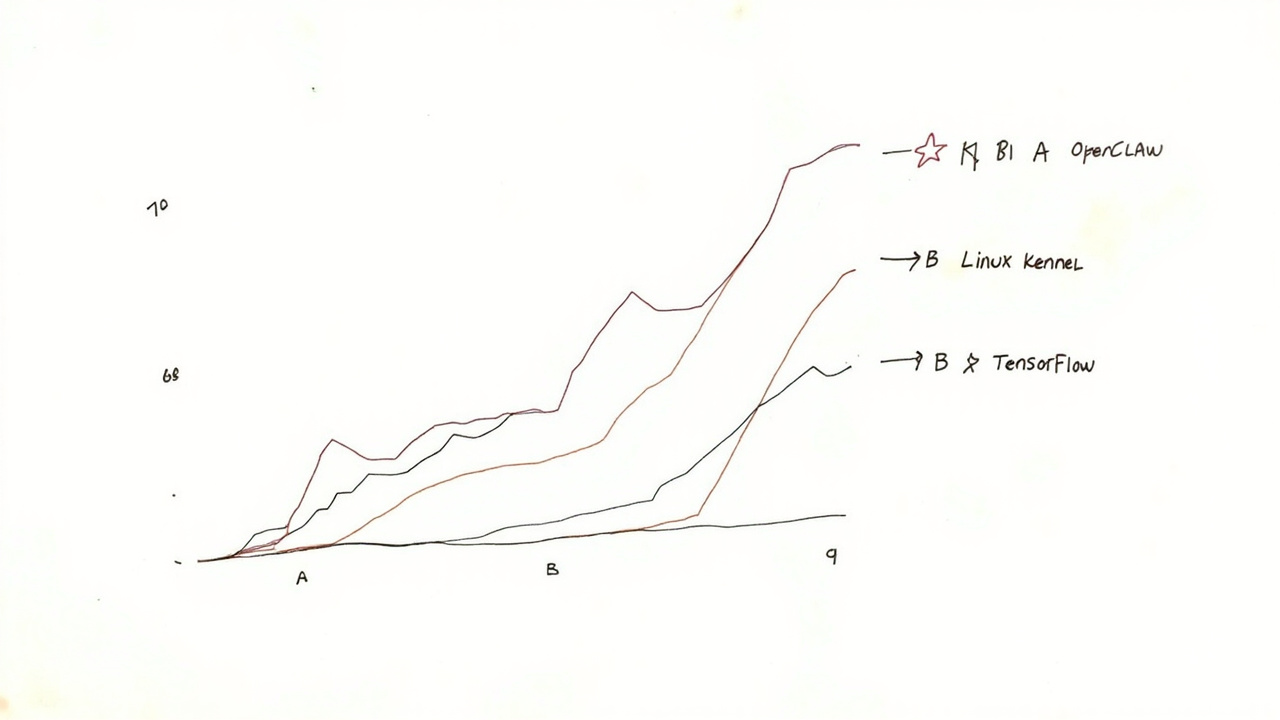
188,000 颗星标背后,是 188,000 个开发者或团队对这个项目的认可。这个数字还在以每天数千的速度增长。
但真正让我惊讶的不是增长本身,而是这种增长是在几乎没有大规模营销的情况下实现的。OpenClaw 的传播几乎完全依靠开发者社区的自发推广——技术博客、YouTube 教程、Twitter 上的讨论、以及 GitHub 上的口口相传。
这说明什么?说明这个工具真的解决了开发者的痛点,而且解决得非常漂亮。
# 四大核心组件:架构之美
深入 OpenClaw 的技术架构,你会发现它的设计理念非常清晰。整体系统由四大核心组件构成:
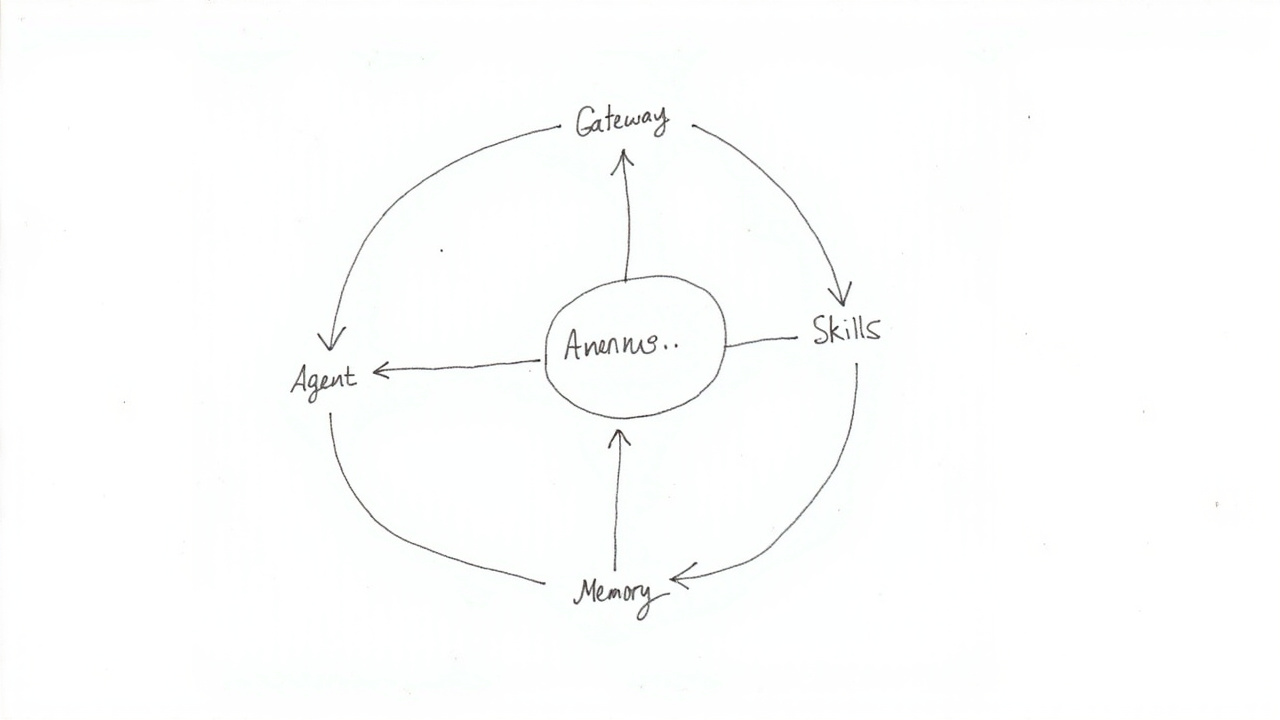
# Gateway:智能路由中枢
Gateway 是 OpenClaw 的"大脑",负责协调所有外部交互。它不仅仅是一个简单的 API 网关,而是一个智能路由系统——能够根据用户意图、当前上下文和可用资源,自动选择最优的执行路径。
举个例子,当你对 OpenClaw 说"帮我分析一下这个 PR 的风险"时,Gateway 会:
- 识别这是一个代码分析任务
- 判断需要访问 git 仓库
- 决定是否需要调用额外的工具(如代码搜索引擎)
- 协调 Agent 执行任务
- 将结果格式化为易于理解的输出
这个过程听起来简单,但背后涉及复杂的意图识别、任务拆解和资源调度。Gateway 的设计让它可以处理从简单问答到复杂多步骤任务的各种场景。
# Agent:真正的执行者
如果说 Gateway 是大脑,那么 Agent 就是那双"能动手"的手。
OpenClaw 的 Agent 不仅仅是一个对话模型,它是一个具备工具调用能力的智能执行体。每个 Agent 都知道自己能做什么、不能做什么,并且能够:
- 访问文件系统
- 执行终端命令
- 调用外部 API
- 与其他服务集成
更重要的是,Agent 支持多 Agent 协作。在复杂任务中,你可以让一个 Agent 负责代码分析,另一个负责文档生成,第三个负责测试验证——它们会像一个小团队一样协同工作。
我在实际使用中发现,这种多 Agent 协作是 OpenClaw 最强大的能力之一。当我需要完成一个完整的功能模块时,我可以让一个 Agent 写代码,另一个 Agent 进行 Code Review,第三个 Agent 生成测试用例。整个过程不需要我反复在不同的工具之间切换。
# Skills:能力的延伸
如果说 Agent 是通用执行者,那么 Skills 就是它的专业工具箱。
Skills 是 OpenClaw 的插件系统,允许开发者为 AI 助理添加特定领域的能力。一个 Skill 可以是一个简单的脚本,也可以是一个复杂的服务集成。
举几个实际例子:
- Git Skills:自动生成符合团队规范的 commit message,分析代码变更的风险
- Database Skills:理解数据库结构,执行 SQL 查询,可视化查询结果
- Documentation Skills:自动更新 API 文档,生成变更日志
- CI/CD Skills:分析构建失败原因,提出修复建议
Skills 的设计理念是可组合、可复用、可分享。这让我们进入下一个话题——ClawHub。
# Memory:持久化的智能
传统的 AI 助手是"无记忆"的——每次对话都是独立的,你无法指望它记住上周讨论的技术决策。
OpenClaw 的 Memory 组件彻底改变了这一点。它提供了多种记忆存储方式:
- 短期记忆:当前会话的上下文,保持对话连贯性
- 长期记忆:跨会话的知识积累,包括项目信息、用户偏好、技术决策
- 结构化记忆:以图谱形式组织的知识,支持语义检索
正是 Memory 让 OpenClaw 能够"越来越懂你"。使用一个月之后,我的 OpenClaw 已经记住了我的代码风格偏好、常用的技术栈、以及我处理问题的习惯方式。当我开始一个新的任务时,它能够自动应用这些知识,提供更加个性化的帮助。
# 本地优先:隐私与掌控
现在,让我们来聊聊 OpenClaw 与传统云端 AI 助手最本质的区别——本地优先。
当我在电脑上运行 OpenClaw 时,所有的数据处理都在本地完成。你的代码、你的文档、你的项目结构——这些敏感信息永远不会离开你的机器。
这不是小众需求。我身边越来越多的开发者朋友开始重视 AI 应用的隐私问题:
- "我不想让公司的代码被发送到第三方服务器"
- "我的客户项目涉及 NDA,不能有任何数据泄露风险"
- "我就是不想让科技巨头们拿到我的使用数据"
OpenClaw 的本地优先架构完美满足了这些需求。它可以完全离线运行,不依赖任何外部服务。即使是模型推理,也可以通过本地部署的模型完成(虽然这需要一定的硬件配置)。
这带来另一个好处:可控性。
使用云端 AI 助手时,你受制于服务提供商的政策——他们可以随时更改定价、限制使用、修改功能,甚至直接关停服务。而 OpenClaw 作为开源项目,代码就在那里,你可以自由使用、修改、部署,没有任何后顾之忧。
# ClawHub:社区驱动的技能生态
如果说 Core 组件是 OpenClaw 的骨架,那么 ClawHub 就是它的血肉。
ClawHub 是 OpenClaw 的官方技能市场,开发者可以在这里分享自己开发的 Skills。从上线至今,ClawHub 的技能数量经历了惊人的增长——从最初的 1,800+ 增长到现在的 13,000+。

这个数字背后是社区力量的体现。开发者们贡献 Skills 的动机很简单——他们自己需要这些工具,而开源精神让他们愿意分享给更多人。
浏览 ClawHub,你会发现各种脑洞大开的 Skills:
- 代码考古学:分析祖传代码,生成"为什么会写成这样"的解释
- 会议纪要生成器:接入日历和会议记录,自动生成结构化纪要
- 周报生成器:汇总你一周的 Git 提交、文档变更和聊天记录,自动生成周报
- 代码风格迁移:将旧代码自动迁移到新的代码规范
我最喜欢的一个 Skill 是 "上下文恢复器"。有时候我被一个 bug 困扰了几天,好不容易找到解决方案后却因为其他事情中断了,等我再回来时已经忘了当时的思路。这个 Skill 会自动记录整个调试过程,包括尝试过的方法、查过的文档、最终解决方案——相当于给每次调试都生成了一份详细的考古报告。
# 与其他产品的对比
在 AI 助理这个赛道上,OpenClaw 不是唯一的选择。让我简单对比一下它与其他主流 AI 助理的差异:
| 维度 | OpenClaw | Microsoft Scout | Claude Agent |
|---|---|---|---|
| 部署方式 | 本地优先 | 云端为主 | 云端为主 |
| 隐私保护 | 极高 | 中等 | 中等 |
| 可定制性 | 完全开源 | 受限 | 受限 |
| 工具调用 | 强大且灵活 | 依赖微软生态 | 通过 API |
| 社区生态 | 快速增长 | 企业客户为主 | 开发者生态 |
| 价格 | 免费 | 订阅制 | API 计费 |
这个对比不是要说 OpenClaw 比其他产品更好——它们定位不同,适合不同场景。Microsoft Scout 在企业集成方面有优势,Claude Agent 在复杂推理任务上表现出色。但如果你像我一样,既想要 AI 的能力,又不想放弃对数据的控制权,OpenClaw 是目前最好的选择。
# 实用场景:我是怎么用它的
说了这么多理论,让我分享几个我实际使用 OpenClaw 的场景。这些场景都是开发者日常工作会遇到的问题,看看你是否能产生共鸣。
# 场景一:代码搜索与重构
上周我需要在一个有 50 万行代码的遗留系统中找到一个 API 的所有调用点。传统的 grep 方式需要考虑各种调用方式、正则表达式、文件类型筛选……
我直接对 OpenClaw 说:"找出所有调用 UserService.getProfile() 的地方,包括直接调用和通过依赖注入间接调用的,生成一个调用链图谱。"
它花了大约三分钟完成了全库扫描,然后给了我一份详细的报告:直接调用点 47 个、间接调用点 23 个、以及一个清晰的调用层级图。
更贴心的是,它还标注了每个调用点可能的上下文风险——"第 3 个调用点可能在事务上下文中,需要特别注意"。
# 场景二:自动化周报
我相信很多开发者和我一样,最讨厌的工作之一就是写周报。我们明明做了一堆事情,却要花半小时去回忆和整理。
现在我养成了一个习惯:每天下班前对 OpenClaw 说一句话,"今天的工作总结",它会自动:
- 抓取当天的 git 提交记录
- 分析代码变更的内容和影响
- 汇总相关的文档更新
- 生成一份结构化的当日工作总结
周五下午,我只需要把这些日总结合并一下,一份完整的周报就出来了。整个过程从半小时缩短到了五分钟。
# 场景三:智能 Code Review
我们团队有自己的 Code Review 规范,但人工检查总是会遗漏一些细节——代码风格不统一、可能有潜在 bug、遗漏的边界情况……
现在每次我提交 PR 后,OpenClaw 会自动进行预审。它会:
- 对比团队的代码规范,检查格式问题
- 分析代码复杂度,指出可能需要重构的地方
- 检查安全风险,如 SQL 注入、XSS 等
- 评估测试覆盖率
最让我惊讶的是,它能理解"上下文"。有一次我提交了一个看起来很简单的变量重命名,但 OpenClaw 提醒我:这个变量在其他模块中有特殊的行为依赖,重命名可能导致问题。后来我查了一下,果然如此——这个潜在 bug 被扼杀在了萌芽状态。
# 场景四:技术债务追踪
每个项目都有技术债务,但债务太多就变成了一笔糊涂账——没人知道具体欠了多少,应该先还哪笔。
我让 OpenClaw 分析了我们的代码库,生成了技术债务报告:
- 按模块划分的技术债务分布
- 每个债务项的严重程度评分
- 推荐的偿还顺序(综合考虑影响范围、修复难度、业务重要性)
这份报告让我第一次对团队的技术债务有了清晰的全貌。我们据此制定了未来三个月的技术债务偿还计划,优先级一目了然。
# 场景五:知识库问答
我把团队的内部文档、设计决策、会议纪要全部同步给了 OpenClaw。现在团队成员遇到问题时,不再需要翻遍 Confluence、Notion 和各种聊天记录——直接问 OpenClaw,它会给出答案,并标明信息来源。
这让知识检索的效率提升了一个数量级。以前找一个问题答案平均需要 15-20 分钟,现在可能只需要 1-2 分钟。
# 为什么本地 AI 助理会爆发?
回到文章开头的问题:为什么本地 AI 助理会在这个时间点爆发?
我的观察是,这是多重因素叠加的结果。
第一,硬件的进步。苹果 M 系列芯片、更好的 NPU 支持、更亲民的本地 GPU 配置……让在本地运行中等规模模型成为可能。几个月前还只能在云端运行的 AI 能力,现在在你的笔记本上就能实现。
第二,隐私意识的觉醒。当我们越来越依赖 AI 处理日常工作,AI 能接触到的数据也越来越多。代码、文档、聊天记录、商业机密……这些数据放在云端让很多人感到不安。本地优先的 AI 助理提供了一种平衡——既享受 AI 的便利,又保留对数据的控制。
第三,开源模型的成熟。Llama、Mistral 等开源模型的崛起,让本地部署有了"灵魂"。这些模型虽然不如 GPT-4 强大,但对于大多数日常任务来说已经足够。更重要的是,开源意味着透明、可定制、不受单一公司控制。
第四,开发者的需求。开发者是最早也是最强烈感受到 AI 价值的群体,但他们也是最挑剔的用户——他们不满足于"能用",他们想要"好用"、"可控"、"可定制"。OpenClaw 正是为这个群体量身打造的工具。
第五,社区的力量。当一个工具足够好用,用户就会变成贡献者;贡献者多了,工具就更好用;更好的工具吸引更多用户……这个正反馈循环让 OpenClaw 的生态以惊人的速度成长。
# 这预示着什么?
OpenClaw 的爆发,让我看到了 AI 产业正在发生的一个深刻转变——从"集中式 AI"向"分布式 AI"的范式转移。
过去几年,我们习惯了"AI 即服务"的模式:所有的 AI 能力都集中在少数科技巨头手中,通过 API 调用。用户获得便利的同时,也交出了数据的主权和对技术的控制。
但开源的力量正在改变这一切。本地优先的 AI 助理不是对云端 AI 的替代,而是一种补充——它让用户有了选择:什么数据放在本地、什么任务交给云端、什么时候依赖第三方模型、什么时候使用自己的模型。
这种分布式、用户主导的 AI 生态,才是 AI 真正走向成熟的标志。
当然,这个转变不会一帆风顺。本地 AI 有自己的局限性:硬件门槛、模型能力的天花板、维护成本……对于很多用户来说,云端 AI 仍然是更实际的选择。
但方向是对的。每一次技术革命都遵循类似的轨迹:从少数人的特权,到大众的工具,再到每个人的基础设施。AI 正在这条路上快速前进。
# 写在最后
回到文章开头老张的故事。
那天凌晨两点给我发消息后,他又发了一条:"我突然理解了为什么 Linux 能打败 Windows —— 不是因为它更完美,而是因为它把控制权还给了用户。"
我没有回复,因为我也在思考这句话的深意。
OpenClaw 给我带来的,正是这种"控制权"的感觉。我不再需要担心我的代码被谁看到、我的使用习惯被谁分析、我的工具哪天会突然涨价或消失。代码在那里,逻辑在那里,我可以理解它、修改它、信任它。
这种感觉,久违了。
金句 1:真正的 AI 革命,不是让机器更聪明,而是让人类重新拿回对技术的控制权。
金句 2:开源的价值不仅在于免费,更在于它让你成为技术的主人,而不是技术的用户。
金句 3:未来的 AI 不会是少数公司的垄断,而是无数开发者的集体智慧——每一个 fork 都是一次进化,每一颗星标都是一次投票。
如果你对 OpenClaw 感兴趣,不妨去它的 GitHub 主页看看。开源的魅力在于:你看到的每一个功能,都可能成为你明天贡献的起点。