上下文越大越好是一个谎言——GitHub 2026 报告里那个被忽视的数字
- 作者:Bougie
- 创建于:2026-07-03
- 更新于:2026-07-03
凌晨两点,我在 Terminal 里把一个看起来很正常的 PR 跑过 CI,diff 几千行。AI 助手洋洋洒洒给我补了一整片工具方法,又自动跑了一遍测试,全绿。我合上电脑就去睡了。第二天醒来,code review 的同事把我从床上叫醒:「这一版里有两个 race condition,三个 N+1,还有个对象莫名其妙被复用。」
我翻回去看,确实是我昨晚没仔细看。但更让我在意的,是他那句轻描淡写的吐槽:「现在 review 你的 PR,比 review 一个应届生的还累,因为你以为它是对的。」
这句话我想了好几天。
不是因为他说的难听,是因为他说的对。
过去两年,整个行业都在追一个数字:上下文窗口。从 8K 到 32K,从 128K 到 200K,从 1M 到 Gemini 2.5 Pro 那种荒谬的「百万 token」。每一家厂商发布新模型的时候,context window 长度一定是 PPT 上最大的那个加粗字。好像只要塞得下整个代码库,AI 就真的能「读懂」你的项目。
然后 GitHub 6 月底出了那份 2026 生态报告,里面有一个数字没什么人提:超过 60% 的开发者,因为盲目信任自动化补全工具,code review 的时间翻了一倍。
翻倍。

这是一个很反直觉的结论。它跟过去三年的所有宣传都不太合拍——「AI 让开发更快」几乎成了行业公理,出现在每一份招股书、每一次财报电话会议里。GitHub 自己的 Copilot 销售团队,拿着 ROI 表格一家一家去说服 CTO 的时候,故事的核心就是「人均产出提升 30%」「代码量提升 55%」「新人上手时间减半」。
但是 review 时间翻倍这件事,是不会被写进销售话术里的。
我自己去翻了一下最近两周的 commit 记录,那种感觉更明显。我把团队里引入大模型接口前后的 PR 数据做了个简单的对比,初始生成速度大概是之前的 3 倍左右,但返工率也同步涨了 40%。3 倍生成,4 成返工——账面上看还是赚的,对吧?但如果你把 review 这件事算上,那 40% 的返工不是免费的:每一个返工的 PR,都要再走一遍 diff、再读一遍逻辑、再跑一遍测试、再做一次评审。整个团队的时间开销,是悄悄被反噬掉的。
更糟糕的是返工率的「形状」。返工的 40% 里,有相当一部分不是「逻辑错了」,而是「逻辑看起来对了,但接不进上下文」。某个变量的命名跟另一个模块的某行代码撞了,某个函数的入参顺序跟上游调用不一致,某个新加的字段在 ORM 里被当作 ignored。这些 bug 单独拎出来都看不出来,因为它们每一处都是合理的、可工作的——但它们凑在一起,就是一个迟早会出问题的系统。
GitHub 的报告里还有一段更狠的话:目前主流 AI IDE 在处理超过 5000 行关联代码时,准确率会呈现断崖式下跌。
5000 行。这个数字在 2026 年看起来非常小。一个中型项目的核心目录,单文件就常常超过 1000 行。一个中后台系统的某个 service 层,五千行只是打底。但模型的「上下文」,是 token 算的,不是行算的。五千行 TypeScript,密集的泛型和工具类型展开后,可能膨胀到 200K token 甚至更多。
这意味着:所谓 1M context window 的模型,对你真正的「可用上下文」,可能只有 5000 行。
剩下的 95% 是噪音,是模型在假装「看完了」。
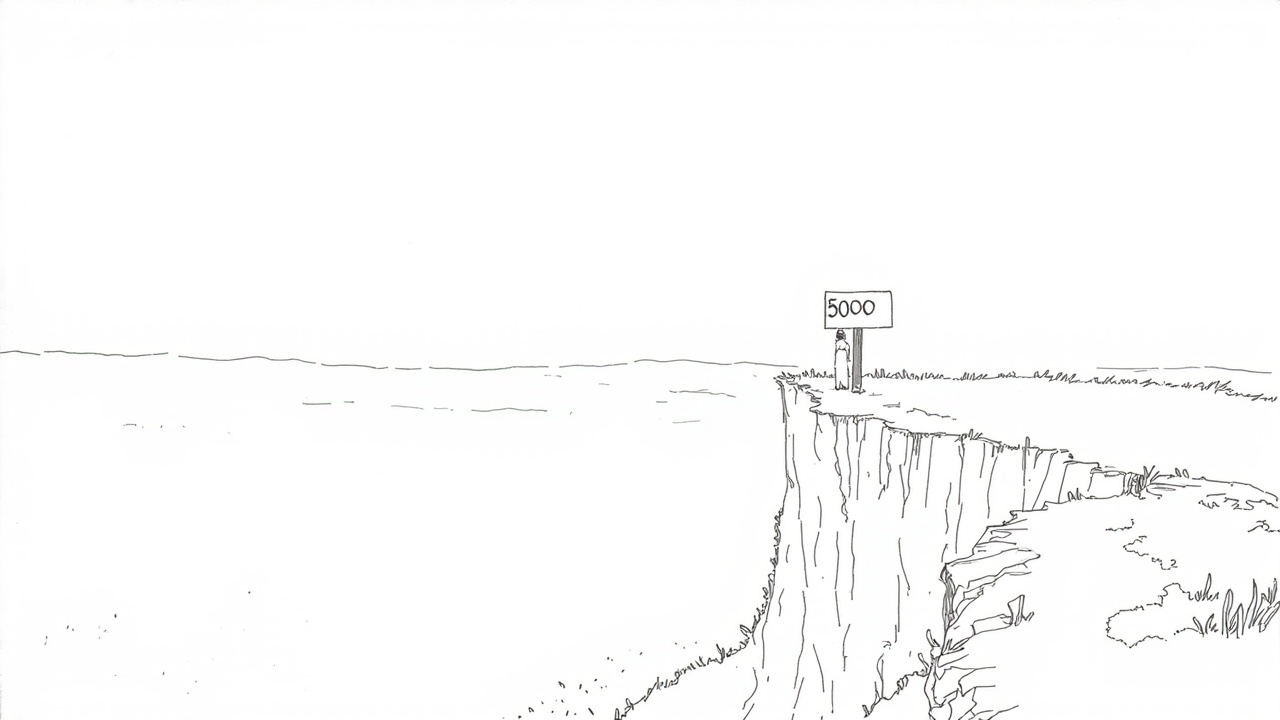
所以真正的反直觉在这里——把更多东西塞进 prompt,并不是在给模型「更多上下文」,而是在稀释它的注意力。模型不是有更强记忆的人类,它是按 token 计算的注意力机器。塞进去的信息越多,每一个 token 分到的注意力就越稀薄,模型就越倾向于生成「看起来对」的东西。
这不是 bug,这是 feature——是 transformer 架构本身的性质。
试图用 1M context 解决「AI 不懂项目」的问题,就像试图用超大行李箱解决「搬家效率低」的问题。箱子越大,你装得越多;装得越多,找东西越慢;找东西越慢,你越焦虑;越焦虑,你就越想装更多东西进去。最后是一个死循环。
我自己这半年最大的调整,其实就一句话:把 prompt 从「塞得多」改成「塞得准」。
具体到操作上,我以前特别愿意把整个项目的入口、配置文件、几个相邻的模块一起塞进 prompt,恨不得让模型「在我打字的时候同步看完整个仓库」。后来发现这是徒劳——模型看完是一回事,看进去是另一回事。
现在我会做几件事,但每件事都不是为了「让模型更聪明」,是为了「让它少看一点」。
按目录切片是关键的一步。项目有十几个子模块,每个模块我留个 200 行左右的「语境快照」——入口、类型、关键抽象——扔进 prompt。剩下的按需检索。需要什么让模型自己去 grep,自己去 RAG,不要让它假装自己全都记得。这件事说起来简单,做起来很容易偷懒,但我跟团队说得很清楚:宁可让模型多花 10 秒去查,也别让它假装懂。
另一个变化是,我越来越相信工具而不是描述。以前我喜欢在 prompt 里写大段大段的代码规范——「请遵循函数式风格」「请不要修改原有签名」「请保持命名一致」——十次有九次被忽略。模型读这些 prompt 跟人读免责声明一样,眼睛滑过去就忘了。现在我会把这些规范变成 .eslintrc、变成 CI hook、变成 pre-commit 检查。模型自己 lint 自己,比我写一万字 prompt 都管用。
还有一个小习惯:我开始给模型限制单次输出的 token 上限。不是给它更多空间写,是给它更小的、更聚焦的任务。一个 200 行的 PR 比一个 2000 行的 PR 更有可能一次写对——不是因为模型在 200 行时更聪明,是因为它在更小的空间里更容易组织自己的注意力。
这几个动作加起来,效果没有 GitHub 销售给你的数字那么夸张——人均产出没有提升 30%,code review 时间也没有直接减半。但返工率从 40% 降回了 18% 左右,PR 平均合并周期从三天缩短到了一天半。
不过最有意思的,还是那份报告里另一个被忽视的方向:当 AI 能力越来越强的时候,开发者和资本开始回流到「搜索」这个环节。
「搜索」——这个 1990 年代的古董。
传统搜索引擎只能覆盖互联网的 20%,剩下的 80%——金融数据、代码库私有内容、企业内部文档——它们都在黑暗里。Agent 越强,它就越需要把这些黑暗里的东西捞起来。于是 AI 搜索基础设施成了一个新热点:AnySearch 这种自建索引的工具,最近半年融了好几轮。Yutori 那种做 proactive agent 的公司,单次 run 要调度 76 个 sub-agent、处理接近 1M token——他们解决的,不是「怎么生成」,是「怎么找到」。

这其实和 context window 的故事是同一条线的另一头——前者是「假装塞得下」,后者是「承认塞不下,所以要更聪明地找」。
我有时候会想,过去三年是不是我们都搞反了重点。模型在变强,窗口在变大,token 在变便宜,但真正的瓶颈——怎么让模型「精准地」拿到它需要的那一小块上下文——从来没被真正解决。
于是大家开始堆 prompt,开始堆 RAG,开始堆 context engineering,开始堆 harness,开始堆 agent 调度。这些工作没有一个是「让模型更聪明」,都是「在模型不够聪明的前提下,怎么管理它的注意力」。
听起来很悲哀。但换个角度,这也是开发者这份工作现在变得更有价值的原因——因为造 prompt 和造代码一样,是一种手艺。
睡前我把那个返工的 PR 重写了一半,删掉了 AI 助手补出来的那一坨工具方法,保留了我自己写的核心逻辑。diff 短了很多,但读起来轻松多了。
我合上电脑,突然又想起来同事说的那句话,又想了想。
「Review 你的 PR,比 review 一个应届生的还累,因为你以为它是对的。」
我决定把这个句子写下来,贴在显示器边上。
不是给我的同事,是给我自己。
每次我想偷懒,让 AI 把整个仓库「看一遍」再告诉我答案的时候,看一眼。
